Nevermined Tech: Nuts & Bolts
Data Availability Tools
8 min readThis post provides a short technical overview of Nevermined’s capabilities.
Nevermined offers its users the ability to build data sharing ecosystems where untrusted parties can share and monetize their data in a way that’s efficient, secure and privacy preserving.
As data creation continues to proliferate, entities have the necessity of organising, understanding, using and sharing their data internally and externally. Nevermined provides Data Availability and Data In-Situ Computation solutions that allow organizations to unlock data for a more insights-driven approach.
What we call a Data Ecosystem is an environment where independent organizations can cooperate with each other to publish, discover, and access data and the associated assets and services. Nevermined enables the usage of data without the members of these ecosystems having to lose control of their assets.
One of the main principles of Nevermined is that Data Owners and Providers always keep control of their data. The solution is designed to be integrated with existing Big Data environments and allows for the execution of models or algorithms in-situ, i.e. where the data resides. With Nevermined, the data never moves; instead the algorithms and models move to where the data sits.
Building Blocks
Nevermined is an advanced data engineering system based on three independent technical capabilities. Each one of them is highly related to the other. And it’s the combination of each that permits the implementation of very interesting solutions. The capabilities are:

- Data Availability, enabling the sharing and access of digital assets between untrusted parties in the data ecosystem
- Data In Situ Computation, allowing the execution of models and algorithms without moving the data
- Marketplace and Catalog, facilitating user interactions with the data ecosystem
Similarly to the heads of the monkey in the picture above, the three building blocks are highly-related. The Data Sharing piece provides the decentralized access control plumbing and facilitates defining service agreements on-chain that can be used to create and execute data services within the ecosystem. The compute piece uses that plumbing to orchestrate an off-chain computation. The marketplaces and catalogs provide the frontend, gluing everything together in a way that is easy to use.
Data Availability
Nevermined enables data sharing capabilities between unstructured parties. The main users involved in this scenario are:
- Organizations that want to share and monetize their data (Data Owners/Providers).
- Organizations or individuals looking for data sets to train their models (Data Users/Consumers).
Typically Data Providers & Consumers don’t know or trust each other and with Nevermined they don’t need to. Nevermined provides a generic solution where both parties can share the access to their data in a decentralized and secure way. The main benefits for them are:
- Data Providers can monetize their existing data
- Data Consumers can get access to datasets they couldn’t get access to under other conditions
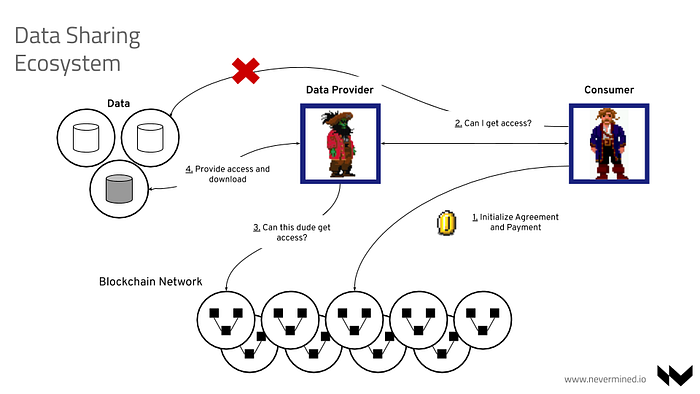
The above diagram represents a situation where a Data Provider owns some data that resides within his premises. A Data Consumer can discover — via a Marketplace or Data Catalog — the new data asset. At a very high level, the steps required to facilitate the data sharing are as follow:
- The Consumer expresses interest in the asset by initializing and signing a Service Agreement on a Nevermined Network. If the access to the asset requires any payment, the Consumer makes the payment to an escrow account.
- The Consumer sends a request to the Data Provider to get access to the asset. This request includes the Consumer signature, service agreement ID and so on.
- The Data Provider validates the signature of the Consumer and whether all the access-providing conditions are met (payment, user, group, etc).
- If everything is verified, the Data Provider decrypts the internal information that provides access to the asset.
Sweet and simple. If you own data and want to get paid for sharing it, you don’t need to move it somewhere else. You only need to run the Nevermined Gateway within the infrastructure where your data already resides to make it accessible. You can find more details about the internals in the Decentralized Access Control Specification.
Data In Situ Computation (DISC)
With the Nevermined Data In-Situ Computation building block, or DISC, we help Data Providers offer computation services to third parties, allowing them to execute algorithms or train models where the data already exists.
This scenario is based on the premise that data doesn’t want to be moved. Moving data from its existing premises is a liability. The data can be leaked in transit and due to the private nature of many types of data, moving it implies some regulatory issues. In such a case, Nevermined provides a solution where the Data Provider allows the execution of an algorithm (Tensorflow, Spark, etc.) in the data’s existing infrastructure. This means
- the Data Consumer provides the algorithm to execute
- this is moved to the Data Owner infrastructure where the data is being stored
- the Data Owner executes the algorithm on behalf of the Data Consumer
- the Data Consumer receives the result of the execution of the algorithm post analysis.
One important characteristic of the Nevermined design is that is independent of the compute backend. Nevermined supports plugging in different compute backends. Depending on the use case, Nevermined will orchestrate the compute jobs in different ways, while the rest of the Nevermined ecosystem stays the same (services, APIs, applications on top, etc.).
Currently, Nevermined integrates 2 different compute backends:
- Federated Learning Backend — It fits the execution of federated learning jobs using the data of providers having federated environments. It allows for the training of models across multiple Data Providers.
- Kubernetes backend — Perfect for compute jobs or services that only involve one Data Provider.
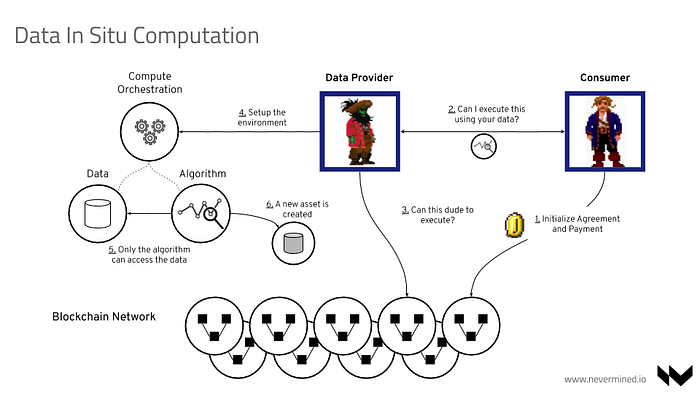
The above diagram has some similarities with the previous one. This is because it shares the same internal patterns and infrastructure we’ve already discussed. In this case, a Data Provider owns some data in his environment. Because of the nature of the data, it’s not possible to provide direct access, so here we want to allow third-parties to send their algorithms/models and the Data Provider will orchestrate the infrastructure allowing the “computation” to be moved and executed in an ephemeral and isolated environment where the data is kept.
A Data Consumer, in this case typically a Data Scientist or Data Engineer, discovers via a Marketplace or Data Catalog that there is a data asset that can’t be downloaded but allows it to be used by a computation job. On a very high level, the steps that are happening to allow the data sharing and access are as follows:
- The Consumer expresses interest in executing some algorithm on top of the data asset initializing and signing a Service Agreement on a Nevermined Network. Typically this also requires making a payment to an escrow account.
- After doing this, the Consumer sends a request to the Data Provider specifying the algorithm to run and the details of the environment required. This request includes the Consumer signature, service agreement ID and so on.
- The Data Provider validates the signature of the Consumer on the Blockchain Network and whether all the access-providing conditions are met (payment, user, group, etc.)
- If everything validates properly, the Data Provider communicates with the Orchestration service. It provides for translation of the computation job requested and facilitates set up the infrastructure required.
- The Orchestration service runs an isolated and ephemeral environment where the algorithm given by the consumer can get access to the data.
- The resulting result of the computation is stored in the environment of the Data Provider and is published as a new data asset in the Nevermined ecosystem. The ownership of this new created asset is transferred to the Consumer.
Part of the orchestration described in the flow depends on the compute backend (Federated Learning, Kubernetes). We will share more details on this soon. In the meantime you can read the lower level details in the Data In-Situ Computation Specification.
Marketplace, Dashboards and Data Catalogs
The last piece is the one putting it all together and exposing an interface that allows the Data Ecosystem users to collaborate. Beyond the web interfaces, Nevermined provides the tools to integrate all the described capabilities via SDKs, allowing the use of Data Ecosystem features from an organization’s existing set of data tools.
The main objective of these tools are to facilitate the search, discovery and management of the existing assets in the data ecosystem. This includes:
- Improved User Experience
- Integration with the Data Governance and Data Catalog tools
- Easy search and discovery
- Native integration with data sharing and DISC building blocks
- Internal data catalog and APIs
- Tokenization and incentives
As you see, all these 3 pieces complement and fit together with the intention of providing a Data Ecosystem where different kinds of untrusted users can collaborate, share and access one another’s data in an easy and seamless way.

Thank you if you were able to reach this part. This has been the first of a list of technical blog posts we are planning to share about some of the Nevermined features and next steps. But if you have any questions or are interested on knowing more, please drop us a line: info@nevermined.io
Useful Links
If you want to know a bit more, here you can find some additional information:
- Nevermined.io website
- Documentation (including architecture & solution specifications)
- Nevermined Github Repositories
And if you want to be in contact with the team or participate in the conversation, you can follow the Nevermined Twitter or join the Nevermined Discord server.
Originally posted on 2020-11-20 on Medium.